Table des matières
LES PDF SOUS LINUX
Les principes du pdf : ce sont des fichiers qui comprennent l’ensemble des informations nécessaires à la présentation en particulier le texte, les images et les polices. Ce dernier point est particulièrement important car les polices disponibles ne sont pas les mêmes d’un ordinateur à l’autre ce qui rend problématique le passage d’un fichier d'un ordinateur à l'autre, à commencer par les documents de traitement de texte DOC ou ODF, d’autant plus que la présentation est un peu élaborée.
Pour plus de détails voir sur Wikipedia : https://fr.wikipedia.org/wiki/Portable_Document_Format
Imprimer un ficher pdf :
Elle peut se faire avec le visionneur de document ou avec un navigateur comme Firefox ou Chromium. Il peut arriver que la fonction d’impression soit désactivée sur le visionneur de document. Dans ce cas il suffit de cliquer à droite et de choisir un navigateur pour ouvrir le ficher.
Faire une recherche dans un fichier pdf :
La fonctionnalité existe aussi bien avec le visionneur de document qu’avec Firefox ou Chromium. Elle ne fonctionne que si le texte est en format texte, ou bien s'il comporte en arrière plan invisible un OCR de l'image. En cas de besoin on peut créer cet arrière plan afin qu'une recherche soit possible.
Annoter dans un fichier pdf des champs à remplir :
Il existe un grand nombre de possibilités plus ou moins satisfaisantes. Sur le principe, on peut soit le faire en local soit avoir recours à un service en ligne.
Outils en ligne
Firefox propose par exemple pdf editor accessible en installant l'extension du même nom

En local
Installer Xournal. Pour l’installation, se reporter à : https://fr.ubunlog.com/outils-pour-travailler-avec-des-pdf-sous-Linux/
Protéger le ficher pdf par un mot de passe :
Utiliser pour cela l’application PDF4QT editor. Pour son installation, se reporter à : https://fr.ubunlog.com/outils-pour-travailler-avec-des-pdf-sous-Linux/
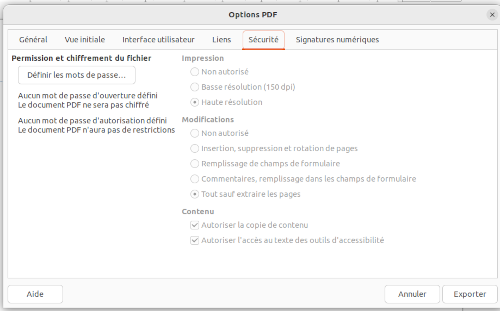
Cliquer sur Encryption.
 Choisir un mot de passe et les options de protection et enregistrer le fichier.
Choisir un mot de passe et les options de protection et enregistrer le fichier.
Recadrer un pdf
En ligne
Avec pdf editor, accessible en installant l'extension du même nom sur Firefox.
Choisir white out. L’outil en fait ne recadre pas exactement mais définit les parties à blanchir ce qui aboutit au même résultat.

En local
avec Krop, pour installer : https://can.linux-console.net/?p=136#gsc.tab=0
Sélectionner la zone à conserver avec la souris, puis cliquer sur Krop
 et sauvegarder :
et sauvegarder :
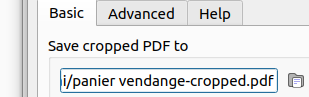 L’application permet aussi de supprimer les marges inutiles.
L’application permet aussi de supprimer les marges inutiles.
Fusion de fichiers pdf, suppression de pages
Ces opérations se font facilement avec PDF Arranger. Pour l’installation : https://fr.linux-console.net/?p=18678 Son utilisation est particulièrement simple. On peut aussi extraire des pages d’un fichier pdf simplement par l’impression en choisissant l’option imprimer en format pdf . Toutefois cette option si elle est pratique à l’inconvénient de générer des fichiers pdf nettement plus volumineux que le fichier de départ, malgré qu’il comporte moins de pages …
Modification du contenu d’un fichier pdf, ou récupération pour un autre usage
(par exemple pour copier dans un traitement de texte ou une autre application) En gros il y a 2 possibilités :
Avec GIMP
si le contenu est principalement une image, il peut être adapté de l’ouvrir avec Gimp. Ce sera par exemple le cas pour un schéma ou un dessin dont les légendes ne sont pas en français et que l’on veut traduire.
Avec libre office Draw
si le contenu est principalement du texte, on l’ouvrira avec draw dans la suite libre office. Toutefois on ne peut pas s’attendre à un résultat parfait car on perd l’avantage du format pdf qui sauvegarde à la fois le texte et les polices. A moins que le document n’ait été produit avec la même application et le même jeu de polices, il est probable que des problèmes de présentation vont se poser.
Dans l’exemple ci-dessous, on voit que le rendu est acceptable pour le corps du texte mais que la taille de la police est inadaptée pour la note de bas de page et que du coup le texte déborde. Par ailleurs, chaque ligne de texte est comprise dans une zone de texte spécifique ce qui empêche de sélectionner tout le texte dont on veut modifier la taille de la police.
 Il faut donc commencer par supprimer ces multiples zones de texte. Pour cela avec la souris dessiner un rectangle de sélection :
Il faut donc commencer par supprimer ces multiples zones de texte. Pour cela avec la souris dessiner un rectangle de sélection :
 Placer la souris sur cette zone jusqu’au moment où une croix apparaît et cliquer à droite.
Placer la souris sur cette zone jusqu’au moment où une croix apparaît et cliquer à droite.
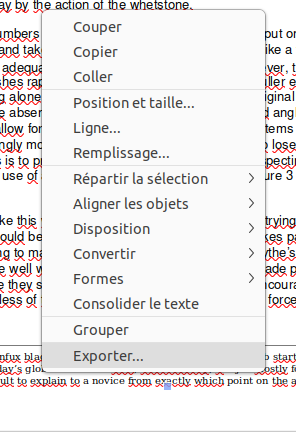 Choisir « consolider le texte ». Les zones de texte sont alors supprimées et il est possible de sélectionner le texte et de modifier la taille de la police pour que le texte rentre dans le cadre de la page, ou simplement comme dans cet exemple étendre la zone de texte vers le bas.
Choisir « consolider le texte ». Les zones de texte sont alors supprimées et il est possible de sélectionner le texte et de modifier la taille de la police pour que le texte rentre dans le cadre de la page, ou simplement comme dans cet exemple étendre la zone de texte vers le bas.
 La même opération peut être faite sur toute la page ou une partie de celle-ci afin de sélectionner le texte ou une partie de celui-ci pour le copier dans une autre application.
La même opération peut être faite sur toute la page ou une partie de celle-ci afin de sélectionner le texte ou une partie de celui-ci pour le copier dans une autre application.
Faire un pdf à partir d’un écrit papier
Deux opérations :
Scanner le document
La technique donnant le plus de possibilités est de le faire à partir de GIMP.
Vérifier tout d’abord que l’ordinateur est configuré pour le faire. En choisissant créer, l’option du scanner doit apparaître :
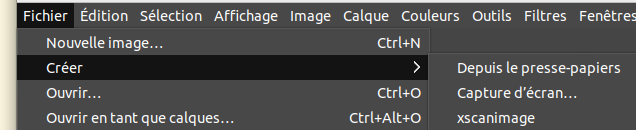 Si ce n’est pas le cas, il faut installer xscan : sudo apt-get -y install xsane (sur le terminal).
Ensuite paramétrer le scan, en règle générale, scanner avec une définition de 300 ou plus, surtout si l’on souhaite procéder à une reconnaissance de caractère ensuite. Demander une préview.
Si ce n’est pas le cas, il faut installer xscan : sudo apt-get -y install xsane (sur le terminal).
Ensuite paramétrer le scan, en règle générale, scanner avec une définition de 300 ou plus, surtout si l’on souhaite procéder à une reconnaissance de caractère ensuite. Demander une préview.
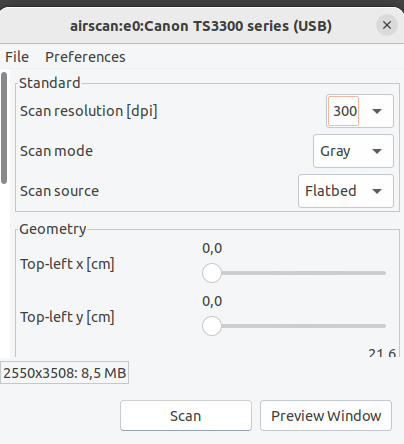 Sélectionner avec la souris la zone à scanner, fermer la fenetre de previsualisation et cliquer sur scanner
Sélectionner avec la souris la zone à scanner, fermer la fenetre de previsualisation et cliquer sur scanner
 Ensuite utiliser les outils de GIMP pour peaufiner le scan : contraste, rotation, recadrage etc…, Exporter le fichier en format pdf dans un sous dossier spécifique établi à cet effet.
Ensuite utiliser les outils de GIMP pour peaufiner le scan : contraste, rotation, recadrage etc…, Exporter le fichier en format pdf dans un sous dossier spécifique établi à cet effet.
 Si le scan a concerné 2 pages, traiter séparément chaque page. De même, si l’original comportait 2 colonnes, traiter séparément chacune des colonnes qui fera donc l’objet d’un fichier pdf spécifique. Cette précaution sur les colonnes n'est nécessaire que si on souhaite procéder ensuite à un OCR.
Puis passer à la page suivante en exportant à chaque fois dans le sous répertoire.
Si le scan a concerné 2 pages, traiter séparément chaque page. De même, si l’original comportait 2 colonnes, traiter séparément chacune des colonnes qui fera donc l’objet d’un fichier pdf spécifique. Cette précaution sur les colonnes n'est nécessaire que si on souhaite procéder ensuite à un OCR.
Puis passer à la page suivante en exportant à chaque fois dans le sous répertoire.
Procéder à la reconnaissance de texte
(ou OCR pour optical characters recognition, RCO en français) Il y a deux possibilités pour effectuer l’OCR, selon le but poursuivi qui peut être :
- indexer le document pour permettre d'y effectuer des recherches,
- en extraire un texte pouvant être repris ou travaillé.
Indexation du fichier
s’il s’agit d’indexer le fichier pour permettre des recherches, ou pour qu’il soit lu par les moteurs de recherche au cas où il soit mis sur un site internet, alors on aura recours à gscan2pdf.
Pour installer gscan, se reporter à : https://doc.ubuntu-fr.org/gscan2pdf. Il faudra également installer tesseract, y compris le fichier du français : https://doc.ubuntu-fr.org/tesseract-ocr
Ensuite ouvrir les fichiers pdf du sous-répertoire avec gscan2pdf en indiquant que le scanner ne sera pas utilisé :
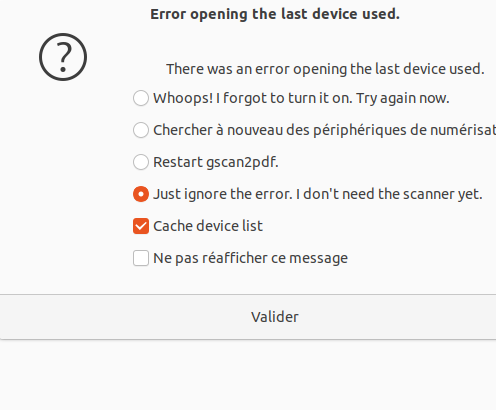 Cliquer sur ROC :
Cliquer sur ROC :
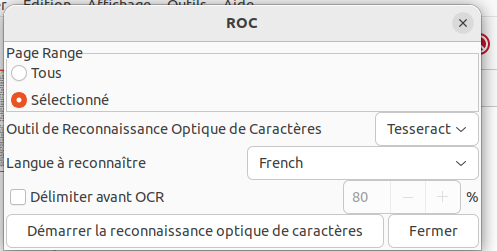 Le texte reconnu apparaît sur « calque du texte ».
Il suffit ensuite d’enregistrer et on obtient un fichier pdf « indexé » où c’est l’image du scan qui apparaît, mais avec la reconnaissance de texte en arrière plan caché ce qui permet d’effectuer des recherches.
En ouvrant ce fichier avec draw, on peut voir les 2 couches :
Le texte reconnu apparaît sur « calque du texte ».
Il suffit ensuite d’enregistrer et on obtient un fichier pdf « indexé » où c’est l’image du scan qui apparaît, mais avec la reconnaissance de texte en arrière plan caché ce qui permet d’effectuer des recherches.
En ouvrant ce fichier avec draw, on peut voir les 2 couches :
 En déplaçant l’image ou en la supprimant on peut faire apparaître la reconnaissance de texte.
En déplaçant l’image ou en la supprimant on peut faire apparaître la reconnaissance de texte.
 La qualité de la reconnaissance de caractère est assez bonne si le scan a été fait soigneusement. Mais la disposition qui vise à la superpostion des mots entre texte et image fait que le texte est très difficile à reprendre. En supprimant les multiples zones de texte on obtient des mots à la suite sans espace dont la reprise demanderait un travail fastidieux.
« Mettonsque,danscetenthousiasme,ilentreunpeud’amour-propredeclocher.
Iln’enrestepasmoinsavéréqueLangresetsabanlieueétaient,autrefois,unerégionquasimentdelégende;quelavieyétaitextraordinaire- »
La qualité de la reconnaissance de caractère est assez bonne si le scan a été fait soigneusement. Mais la disposition qui vise à la superpostion des mots entre texte et image fait que le texte est très difficile à reprendre. En supprimant les multiples zones de texte on obtient des mots à la suite sans espace dont la reprise demanderait un travail fastidieux.
« Mettonsque,danscetenthousiasme,ilentreunpeud’amour-propredeclocher.
Iln’enrestepasmoinsavéréqueLangresetsabanlieueétaient,autrefois,unerégionquasimentdelégende;quelavieyétaitextraordinaire- »
Obtenir un texte pouvant être repris
s’il s’agit d’obtenir un texte pouvant être repris et travaillé, on aura recours à gimagereader. Pour l’installer : https://doc.ubuntu-fr.org/gimagereader.
Le plus simple est de créer un sous répert
oire avec les fichiers images scannés et de charger ce sous répertoire dans gimagereader (2e icône).
 La reconnaissance est relativement longue, avec une barre d’avancement en bas à drroite.
Le texte reconnu figure dans la fenêtre de droite :
La reconnaissance est relativement longue, avec une barre d’avancement en bas à drroite.
Le texte reconnu figure dans la fenêtre de droite :
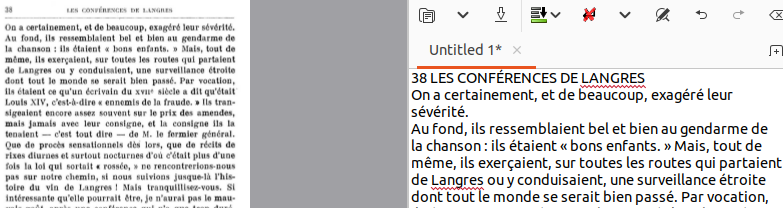 La cinquième icône permet de supprimer les sauts de ligne, elle est précieuse pour pouvoir reprendre le texte.
La cinquième icône permet de supprimer les sauts de ligne, elle est précieuse pour pouvoir reprendre le texte.
 Ensuite on peut récupérer le texte soit en le copiant, soit en enregistrant un fichier texte (3e icône)
Ensuite on peut récupérer le texte soit en le copiant, soit en enregistrant un fichier texte (3e icône)
 Le résultat est globalement excellent quand le but est de reprendre le texte. Cela peut aussi être utile quand on souhaite demande une traduction automatique d’un texte imprimé en langue étrangère. Evidemment il faudra au préalable charger la version de tesseract adaptée à cette langue.
Le résultat est globalement excellent quand le but est de reprendre le texte. Cela peut aussi être utile quand on souhaite demande une traduction automatique d’un texte imprimé en langue étrangère. Evidemment il faudra au préalable charger la version de tesseract adaptée à cette langue.
Exemple d'un document ancien numérisé comme ci-dessus : https://vita-in-vines.ailes-52.org/site/html/vin_de_langres.html
Note importante sur la reconnaissance de texte
Ces 2 méthodes de reconnaissance de caractère ont pour point commun de s’appuyer sur Tesseract. Il est donc indispensable que l’articulation entre Tesseract et gimagereader ou gscan2pdf se fasse correctement. Sinon un message d’erreur apparaît.
Avec gimagereader, le chemin attendu peut être affiché :
 Il est donc possible de vérifier avec l’explorateur de fichier si les fichiers se trouvent au bon endroit.
Exemple de fichiers présents :
Il est donc possible de vérifier avec l’explorateur de fichier si les fichiers se trouvent au bon endroit.
Exemple de fichiers présents :
 Avec gscan2pdf les chemins n’apparaissent que dans un message d’erreur quand la reconnaissance de caractères ne peut se faire. Dans un cas comme dans l’autre, vérifier que les fichiers et les chemins correspondent.
Dans le cas contraire, il est possible d’y remédier. Mais ce n’est pas possible avec l’explorateur de fichiers, il faut procéder avec le terminal en faisant précéder l’instruction par sudo. Cela suppose donc un minimum de maîtrise de l’utilisation du terminal.
Avec gscan2pdf les chemins n’apparaissent que dans un message d’erreur quand la reconnaissance de caractères ne peut se faire. Dans un cas comme dans l’autre, vérifier que les fichiers et les chemins correspondent.
Dans le cas contraire, il est possible d’y remédier. Mais ce n’est pas possible avec l’explorateur de fichiers, il faut procéder avec le terminal en faisant précéder l’instruction par sudo. Cela suppose donc un minimum de maîtrise de l’utilisation du terminal.
Produire un pdf à partir d’un nouveau document :
Dans le plupart des cas on va partir de libre office. La fonction export en format pdf fonctionne bien avec toutes les fonctionnalités de libre office .
 Une autre possibilité est de passer par la fonction impression en choisissant « imprimer dans un fichier ». Mais généralement cela aboutit à un pdf moins bien optimisé et ce n’est donc à faire que dans des cas particuliers.
En cas de besoin, on peut protéger le document par un mot de passe :
Une autre possibilité est de passer par la fonction impression en choisissant « imprimer dans un fichier ». Mais généralement cela aboutit à un pdf moins bien optimisé et ce n’est donc à faire que dans des cas particuliers.
En cas de besoin, on peut protéger le document par un mot de passe :